
L’architecture de l’information est l’étape qui consiste à catégoriser et structurer l’ensemble des contenus ou plus largement, l’information d’une solution numérique, puis de traduire cette structure en une hiérarchie de navigation logique pour garantir une navigation fluide et intuitive.
“Information architecture is the practice of deciding how to arrange the parts of something to be understandable.”
—The Information Architecture Institute
Modèle de la grande distribution
Malgré les innombrables marques et la diversité des enseignes, les rayonnages des établissements de la grande distribution sont souvent conçus de manière similaire. Ils sont organisés par rayon, eux-mêmes rangés par catégorie de produits (le vrac, les fruits, les produits ménagers, les produits du petit-déjeuner…). Diverses raisons ont conduit à cette organisation : espace disponible, gestion des stocks, visibilité des produits… Même si des variations existent, dans l’ensemble, cela permet d’offrir une expérience d’achat fluide et cohérente, en tout cas sur la compréhension de l’emplacement des produits.
Les clients sont habitués à un type de rangement, en fonction des conventions et des standards culturels. Tous les groupements que nous connaissons sont le fruit d’apprentissage. Ainsi, le rayonnage par ordre alphabétique ou par taille est peu courant dans les supermarchés français : la moutarde ne se trouve pas rangée à côté de la mousse à raser (rangement par ordre alphabétique) ou de la confiture (rangement par ordre de taille).

Dans le monde du numérique, c’est la même chose ! Vous devez trouver la meilleure façon de structurer les contenus en fonction des logiques d’organisations collectives et guider les visiteurs pour qu’ils atteignent leur but facilement et rapidement. Mais, vous devez aussi prendre en compte les attentes business et les contraintes techniques. Pour y parvenir, plusieurs étapes sont nécessaires.
Profils et schémas mentaux
Lors de la conception d’un produit, il est essentiel de comprendre pour qui l’on conçoit. Le premier travail de l’architecte de l’information consiste à identifier les profils d’utilisateurs, les cas d’usage, les problèmes qu’ils essaient de résoudre, les standards partagés par le plus grand nombre… En d’autres termes, il tente de savoir qui sont les utilisateurs ? Que font-ils ? Pourquoi le font-ils ? Comment le font-ils ?
À l’issue de cette collecte, ces données vont permettre de :
- Comprendre comment les individus organisent mentalement les informations. C’est ce qu’on appelle “les schémas mentaux” des utilisateurs.
- Structurer les informations de manière à répondre aux schémas mentaux des utilisateurs.
- Proposer différentes manières d’effectuer la même action.
Répertorier le contenu
Ouvrez Excel, c’est parti ! Après avoir identifié l’ensemble des contenus d’un site web, d’un logiciel ou d’une application, c’est-à-dire toutes les pages ou fonctionnalités existantes, un premier tri est réalisé. De fait, il s’agit de supprimer les pages obsolètes, en doublon, sans pertinence. La vision et les objectifs de la solution doivent être clairement définis à cette étape pour optimiser ce travail d’inventaire.
De plus, de nouveaux contenus peuvent être ajoutés. Le but de cette étape est de disposer d’une base de données de l’ensemble de contenus, alignée avec les attentes business et les besoins des utilisateurs.
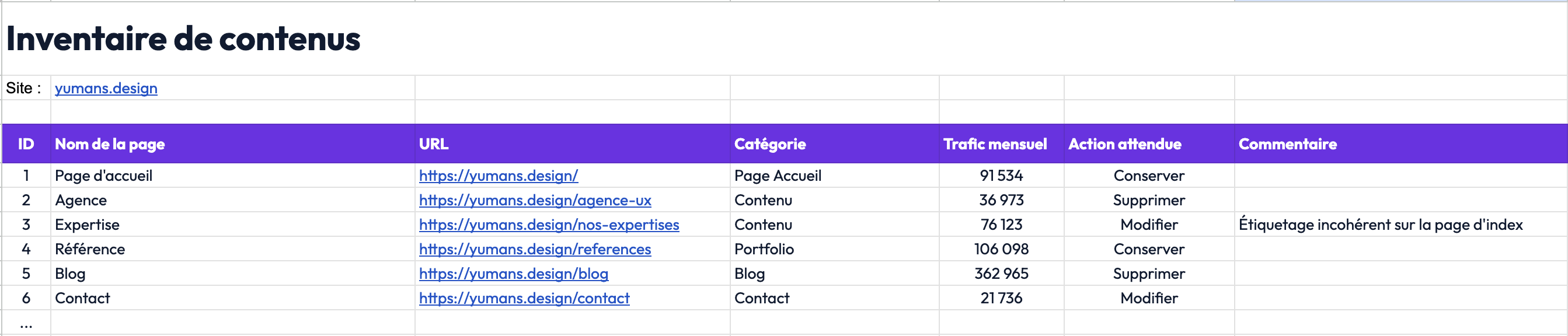
Sans surprise, plus un site est riche en contenus, plus cette étape peut s’avérer complexe et fastidieuse, surtout si l’architecte de l’information est un prestataire. Une prise de connaissance du contenu de l’ensemble des pages est nécessaire. Dans ce cas, un travail avec un binôme en interne est souvent mis en place.
Regrouper pour simplifier
Une fois les contenus et les fonctionnalités nettoyés et actualisés /!\attention, on ne parle pas d’un point de vue du contenu éditorial, l’architecte de l’information doit les classer par catégorie et par ordre de priorité en fonction des schémas mentaux des utilisateurs finaux. La mise en œuvre d’un système mêlant plusieurs schémas d’organisation est idéale.
Dans le cas d’une application, d’un logiciel ou d’un site web, l’architecte de l’information devra se rapprocher des standards collectifs, connus et partagés par le plus grand nombre :
- Dans le cas d’un site web, il s’appuiera sur les normes établies, issues des apprentissages précédents.
- Dans le cas d’une application métier, un système d’organisation différent peut être mis en place, en fonction des spécificités métier et des potentielles contraintes techniques. Très souvent, les contenus sont regroupés par tâches utilisateurs. Un temps d’apprentissage est nécessaire pour prendre en main l’outil et les différentes structures de navigation inhérente au métier. Cependant, cela ne signifie pas pour autant qu’il faille tout réapprendre. Basez-vous sur les logiques d’organisations collectives, partagées par le plus grand nombre lorsque cela est possible.
Information Architecture for the World Wide Web distingue deux catégories de critères d’organisation.
=> Exacts : alphabétique, chronologique, géographique… lorsque les utilisateurs savent ce qu’ils recherchent.
=> Ambigus : tâche utilisateur, thème, audience… lorsque la classification s’opère par ce qui lie horizontalement ou verticalement des informations entre elles, sans vérité générale.
Structurer l’information
Cette étape consiste à construire les logiques de navigation et les modalités d’accès aux contenus, c’est-à-dire la manière dont les pages et les sections sont rangées et connectées les unes aux autres. La diversité dans les différents scénarios d’accès est à privilégier.
La structure organisationnelle hiérarchique la plus connue s’appelle l’arborescence. Cette dernière suit une progression par niveau de profondeur.

D’autres structures existent comme :
- La structure organisationnelle séquentielle qui est linéaire et par étapes (ex : Tunnel d’achat).
- La structure organisationnelle analogique (ex : Wikipédia).
- La structure organisationnelle matricielle (ex : Navigations à facettes).
Des nouveaux parcours peuvent être créés. Comme cela fut le cas pour nos travaux avec Milan Jeunesse, qui a permis de faire émerger trois grandes typologies de parcours utilisateurs.
Conseils pour le nommage
Le nommage est important car le référentiel, le vocabulaire utilisé, doit être celui des utilisateurs finaux. Oubliez les acronymes, les termes barbares et autres anglicismes si vous concevez pour un site grand public. A contrario, dans la conception d’une application métier, les termes choisis par le designer peuvent être inadaptés car pas assez spécifiques. Par exemple, un chirurgien orthopédique ne parlera pas d’une rupture des ligaments croisés mais d’une LCA. Ça ne s’improvise pas !
Pour tester le nommage des entrées de l’interface, analyser le vocabulaire utilisé par les solutions concurrentes, réaliser un tri par carte ou alors explorer l’historique des recherches.
Dernier conseil, plus on s’enfonce dans les niveaux inférieurs de l’arborescence, plus le vocabulaire peut devenir spécifique et cibler une population avertie.
Ramification des parcours utilisateurs
Nouveau défi : Proposer différentes manières d’accéder à une information ou une finalité précise. C’est LE “game changer” d’une solution pensée pour améliorer l’expérience utilisateur. Pour y parvenir, le designer doit prévoir différents parcours utilisateurs à partir des schémas mentaux identifiés.
C’est par exemple le cas du triptyque “Menu / Moteur de recherche / Accès rapide”, très courant dans les sites grand public. Il pare aux différents cheminements des usagers et permet au plus grand nombre d’accéder à l’information selon leurs usages web.
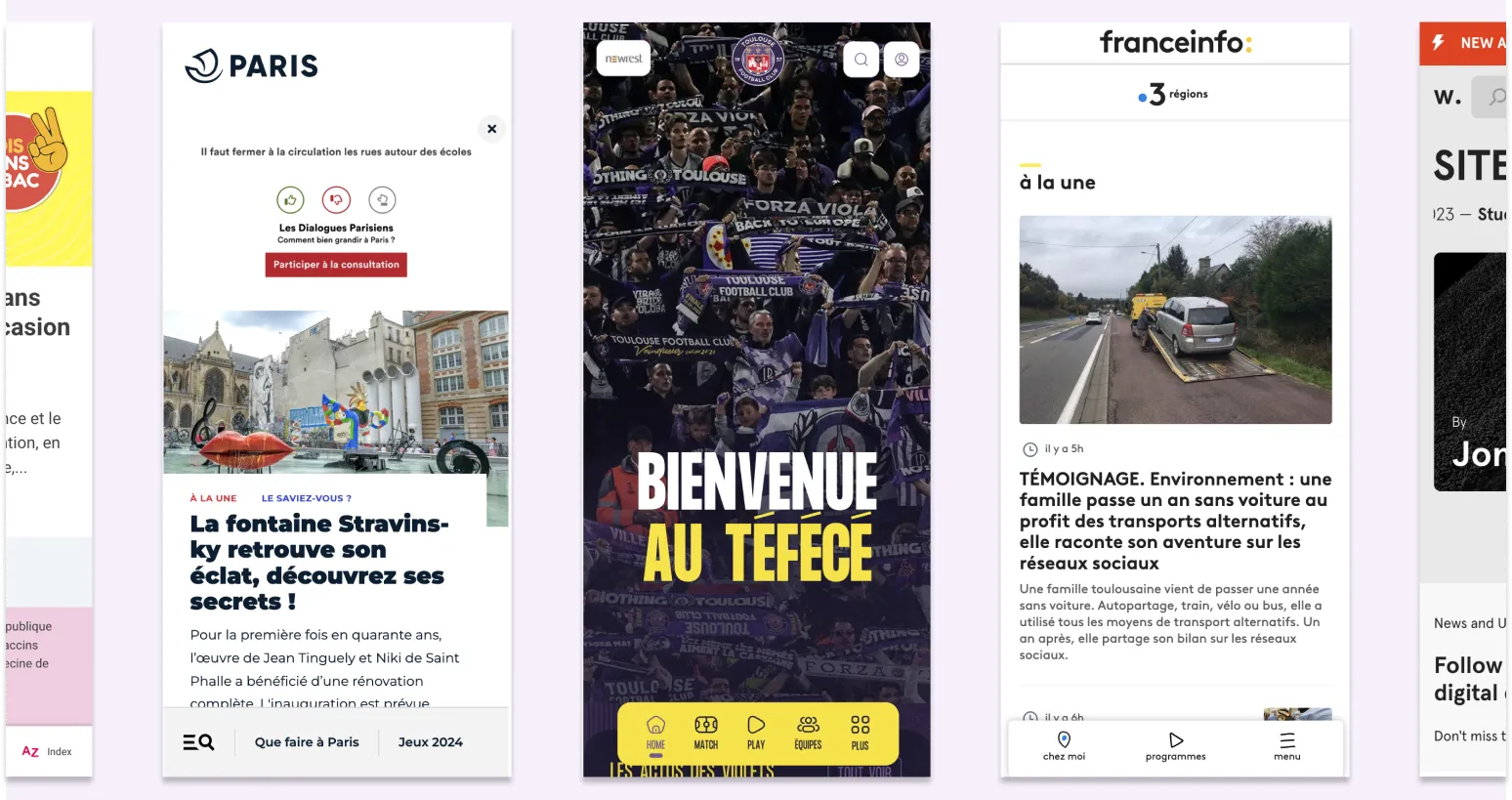
Cependant, il n’est pas possible d’identifier l’ensemble des parcours utilisateurs, pour toutes les fonctionnalités. Il y a toujours les fameux Edge cases.
Méthodes et outils
En fonction des enjeux et de l’étape du projet, l’architecte de l’information peut être amené à réaliser différents types d’atelier ou de test.
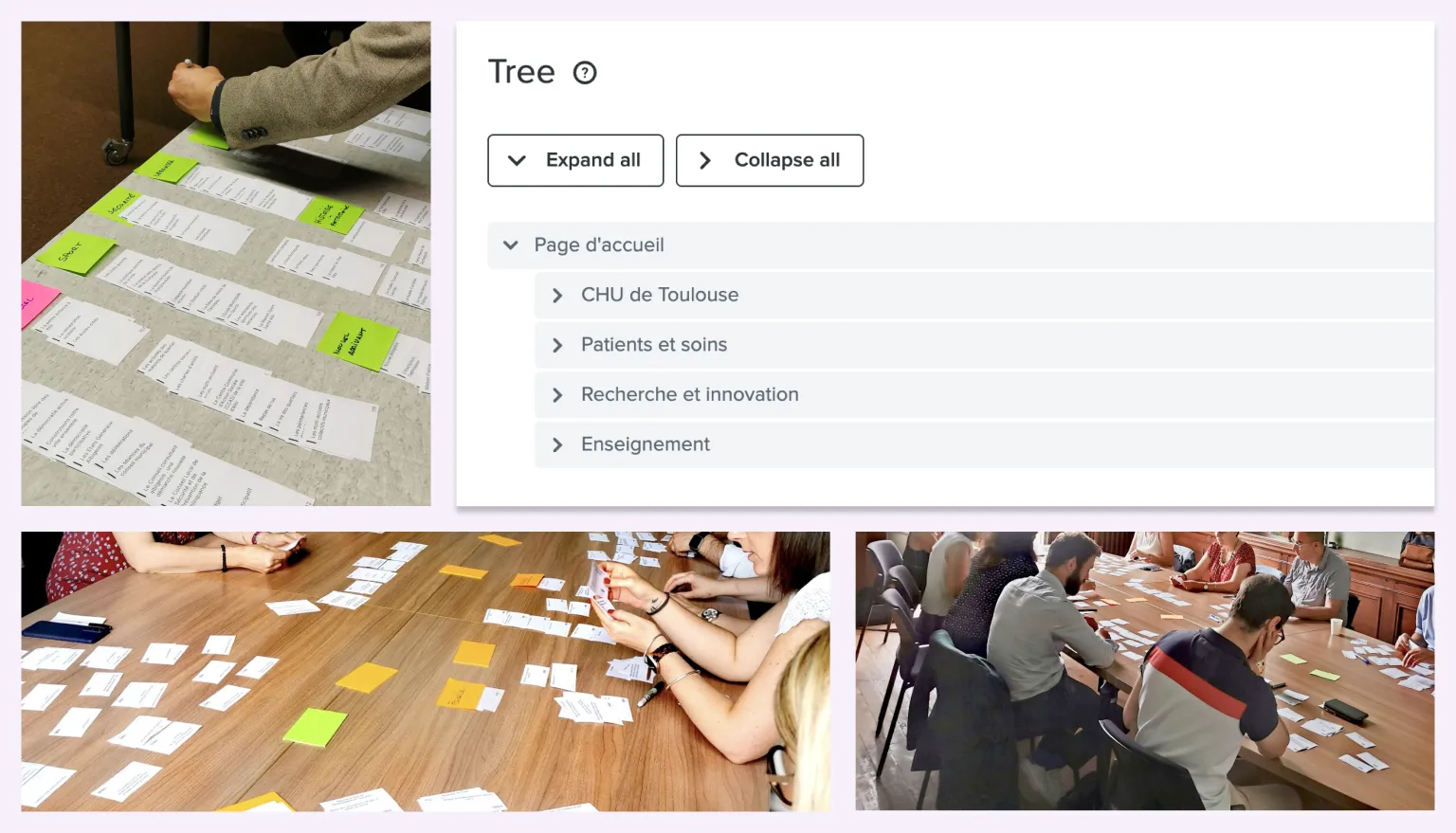
La méthode la plus connue s’appelle le tri par cartes. Il peut être :
- OUVERT pour identifier le regroupement de contenus et le nommage des catégories.
- FERMÉ pour tester l’arborescence réalisée à partir des catégories créés.
- LIMITÉ À DES TÂCHES définies pour confirmer / infirmer la structure de navigation voire d’affiner la terminologie des entrées. L’outil Treejack est très utile pour ce type de travaux.
Conclusion
Les défauts d’organisation sont une des principales causes pour lesquels les internautes trouvent un site compliqué et mal conçu. Le concepteur doit trouver la meilleure manière de structurer le contenu en fonction des critères utilisateurs, business et techniques afin d’apporter une navigation optimale aux usagers.
Jetez un œil à nos autres articles

Concevoir l’erreur comme une expérience à part entière
Dans la plupart des projets digitaux, on accorde beaucoup d’attention au…

IA & Product Design : principes UX pour faciliter les usages
L’intelligence artificielle s’invite dans nos interfaces avec son lot de…

Concevoir une application mobile, entre idéal et pièges à éviter.
Dans un monde où le mobile est omniprésent, créer une application performante…